2 ELT
Consider the following examples to establish a data pipeline.
1. A zip file lands in data lake (s3/minio) daily.
2. Execute scripts in the server (ec2) to download/unzip/select/upload files based on mtime. It produces a file (csv) to track work done at the agreed cut-off time (cron). AWS lambda is another option.
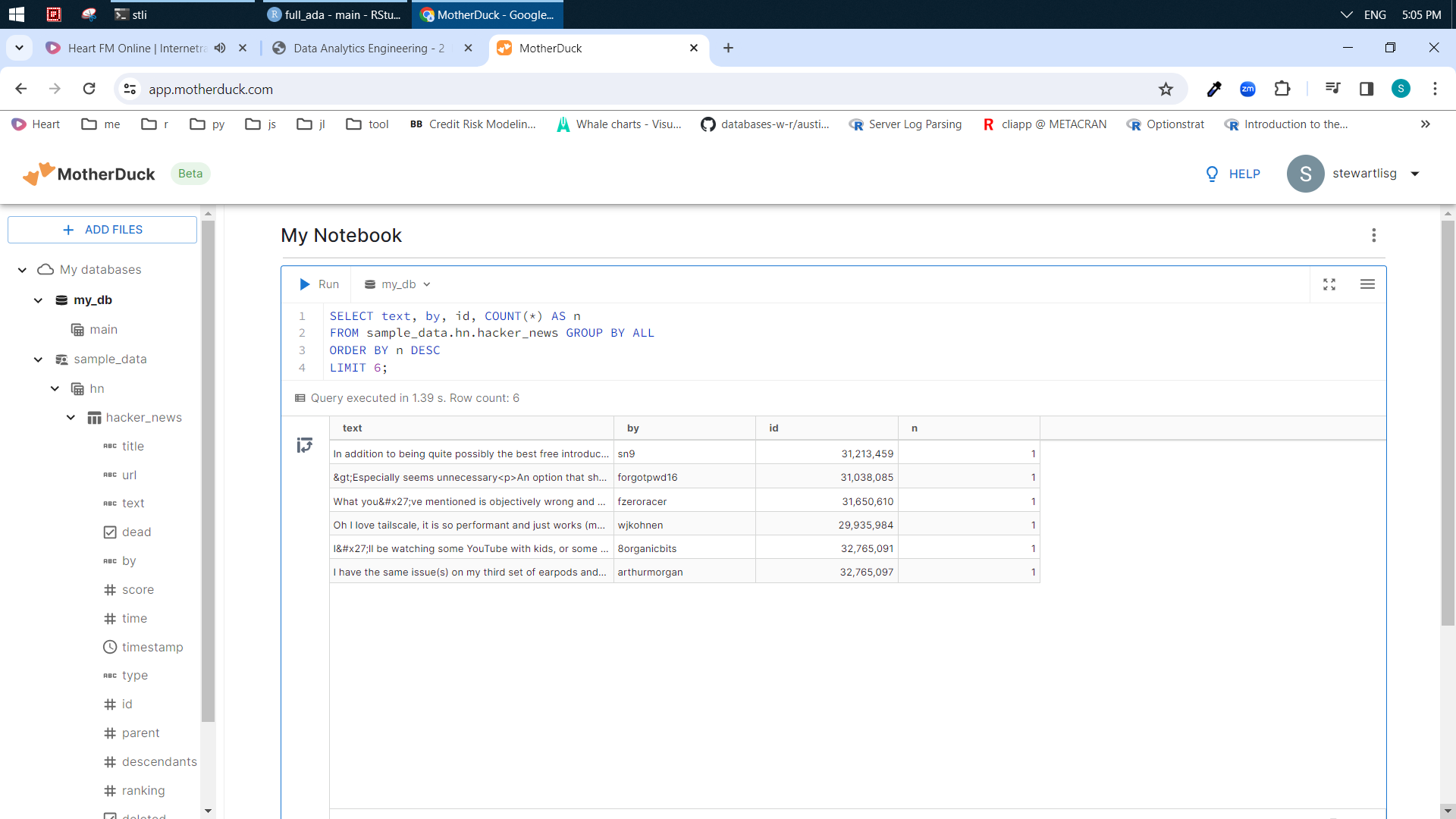
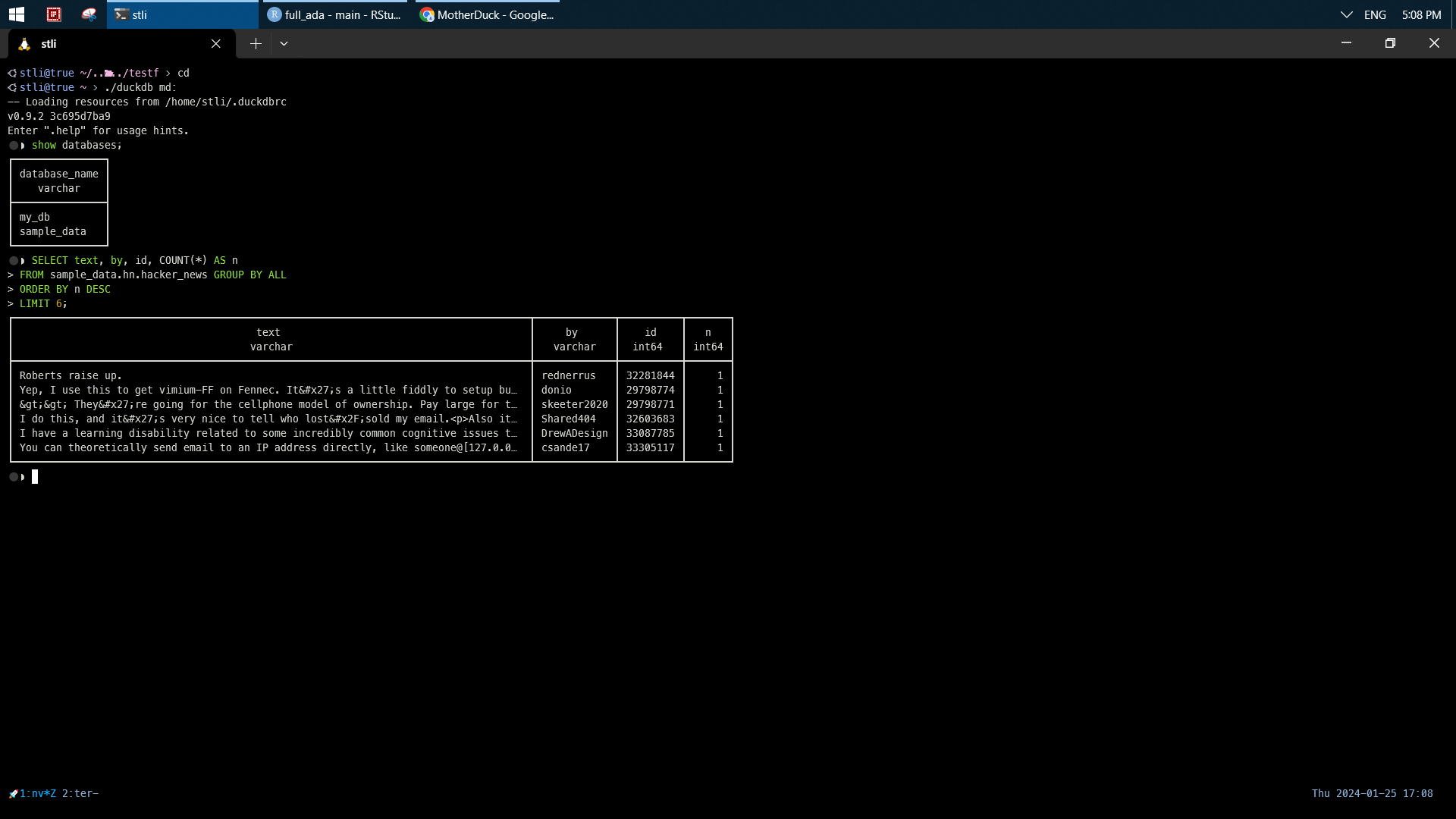
3. snowflake external stage (s3) is triggered by a file (txt) to kicks off snowpipe and ingest data to DB as variant. Similar storage are databrick, dremio, clickhouse. The preferred formats are parquet, iceberg, ADBC.
4. Move data between platforms via airbyte.
5. Validate and transform DB raw to DB mart through dbt.
6. Automatize the process by a task scheduler prefect, airflow, dagster.
7. Create a dashboard for DB mart via metabase, superset.